

Googleが重複コンテンツチェックし検知する技術の特許
パンダアップデートの生みの親が出願した特許をご紹介します。
公開日:2014年06月26日
最終更新日:2025年01月09日

みなさんこんにちは。アナリストの荒木です。
2014/5/20に検索アルゴリズムのパンダアップデート4.0が導入されました。
▼マット・カッツ氏の発言
Growth Seedの順位変動率(現在閉鎖中のツール)は5/20~5/24にかけて大きく変動し、5/24に最高1.36の数値を記録しています。順位変動率は2000キーワード×100URL(つまり20万URL)の変動をモニタリングしています。今回のアップデートでは、そのURLが前日比平均1.32倍も変動したことから、検索アルゴリズム全体にインパクトがあったと推測しています。
パンダアップデートアルゴリズムは2012/7/18にバージョン3.8のタイミングで日本へ初めて導入されました。したがって、4.0は日本導入以来初の大きなバージョンアップといえます。
今回はこのパンダアップデートの生みの親であるNavneet Pandaさんが出願した特許をご紹介します。
本特許では、従来のエンジンが算出するスコアをリンク数を用いて修正する手法が掲載されてます。
※本特許に掲載されている技術はNavneet Pandaさんが出願したというもので、パンダアップデートアルゴリズムというわけではありません。
また、Googleの検索アルゴリズムに導入されている保証もありませんのでご注意ください。
ご紹介する特許の全文は、下のリンクからご覧いただけます。
(別ウィンドウで表示されます)
今回取り扱う特許:Ranking Search Result
今回ご紹介する検索アルゴリズムは、一つのサイトから同じページへ発リンクされている場合、1本あたりの効果を弱める効果があります。
↓【無料DL】「SEO内部対策チェックシート」を無料ダウンロードする
アルゴリズムの概要
検索エンジンは質の高いページを評価することに注力していますが、意図していないページに対しても高評価を与えてしまうことがあります。
本特許では、質の低いページであれば、スコアを低くする仕組みを導入し検索結果を向上させる方法を提案しています。
※質の低いページを定量化する手法が書いてあり、人力で行う手動ペナルティとは異なりますのでご注意ください。
実際の式を見てみると、様々なサイトから受けるリンクとユーザーの認知度に応じてスコアを調整しています(数式の詳細は後半で説明いたします)。
例えば、指名クエリ(サイトを指名する検索ワード)による検索数は少ないが、様々なサイトからリンクを受けているページはスコアに加点します。逆に、指名クエリはたくさんあるが、様々なサイトからのリンクがない場合はスコアが減点されます。
以下はシステム概要図です。本特許のメイン部分を赤色で塗りつぶしています。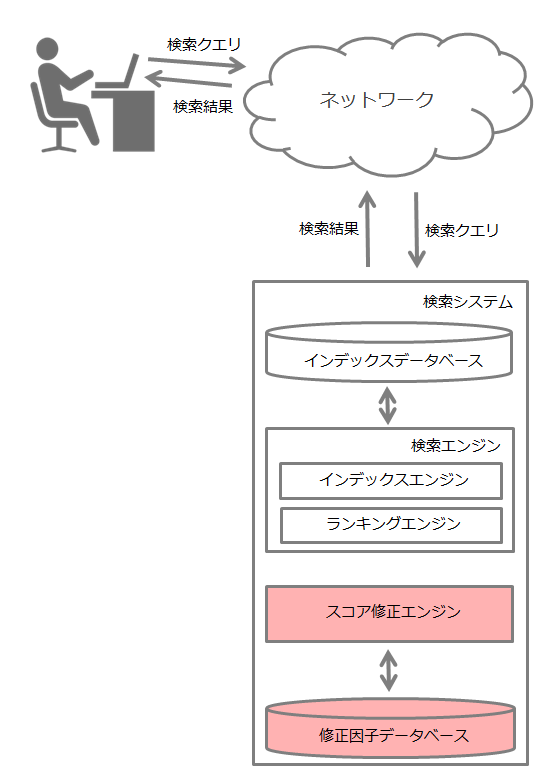
以降はフローチャートや数式を用いて説明します。
苦手な方は読み飛ばしていただき、まとめをご覧ください。
スコア算出のフロー
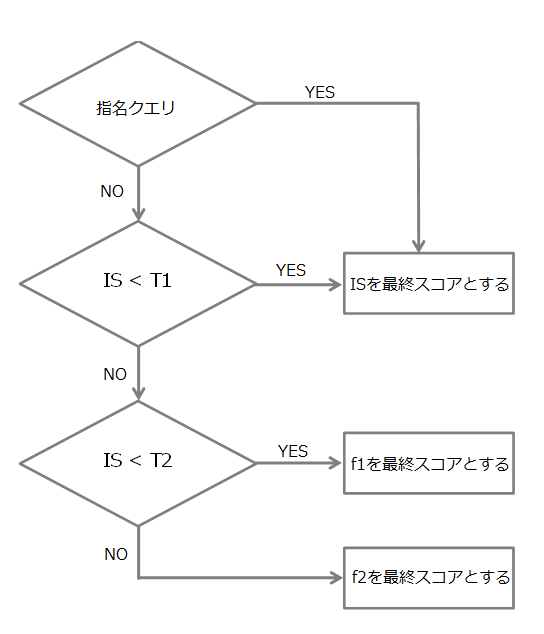
※IS:Initial Score(イニシャルスコア)の略。ランニングエンジンが算出したスコア。
f1,f2:スコア修正エンジンが算出したスコア。
T1,T2:最終スコアを計算する分岐に用いるしきい値。
まず、クエリが入力されるとサイト名等を示す指名クエリか否かを判断します。
指名クエリの場合は検索エンジンが算出したISを最終スコアとします。
指名クエリのではない場合、ISとしきい値を比較します。
ISがしきい値(T1)よりも小さい場合はISを最終スコアとします。
しきい値(T1)よりも大きい場合はスコアを修正します。
スコアを修正する場合、ISと上記とは別のしきい値(T2)と比較します。
ISがしきい値(T2)よりも小さい場合、f1を最終スコアとします。
しきい値(T2)よりも大きい場合はf2を最終スコアとします。
以降では、f1とf2について詳細な説明を致します。
SCORE MODIFICATION ENGINEが算出するスコア
【その1:f1】
T1以上T2未満のスコアを持つページは以下のとおり再計算されます。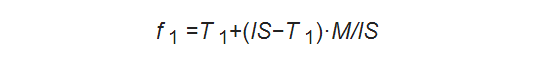
T1はしきい値、ISはInitial Score、Mは修正因子であり、スコアを変化させるキモの要素でM=IL/RQによって求めます。
ILはIndependent Linkの数:リンク数は貼られてなければ0、100本貼られていても同一サイトならば1と計上します。
RQはReference Queryの数:指名クエリの数を計上します。
(例)www.example.comのReference Queryは「example.com」を含む全ての検索クエリが該当します。
上記の式から以下の事がわかります。
f1は様々なサイトからのリンクが多くなる程スコアが高くなり、指名クエリ数が多い程スコアが低くなる。
【その2:f2】
T2以上のスコアを持つページは以下の通り再計算されます。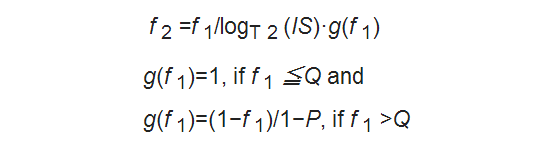
Qは予め決めておいたしきい値で、実装上f2の分母は常に1より小さい値に調整しています。
従って、f2は常にf1よりも大きな値をとります。
まとめ
今回ご紹介した検索アルゴリズムの特許は、サイトワイドリンクなど同一サイトから多数貼られている場合、そのリンクの評価をほとんど無視することで、品質が高く見えていたサイトのスコアが下がるように調整されています。
また、リンク数と指名クエリ数を同じ土俵にのせることで、検索されているが他のサイトから紹介してもらえていないサイトはスコアを下げる様に調整されています。
質の良し悪しを定量化することは難しいですが、検索クエリ数とリンクを使って「人の評判」から質の高いページへアプローチする手法がとても勉強になりますね。
余談ですが、マット・カッツ氏が「サイトワイドリンクをうまく束ねて評価する事が、アルゴリズムで出来ている」と2012/11/13にYoutubeで発言しています。
もしかしたらこの特許に出ているIndependent Linkがこの発言を産んだかもしれません。
また、導入の有無は別にしても、検索アルゴリズムの特許を読むと、検索ユーザーに最高の体験をさせるためにGoogleが考えていることがわかる気がします。
【追記】Googleはパンダアップデート以外にもさまざまなアップデートを実施しています。Googleのアップデートの歴史をまとめた解説記事を公開していますのでご興味のある方はご一読ください。
長文にお付き合い頂きありがとうございました!
株式会社フルスピードのSEO関連サービスのご紹介
-

Webサイト
コンサルティングSEO、コンテンツSEO、UIUXの三軸でアプローチし、流入数・コンバージョンをアップさせます。 -

SEOコンサルティングサイト課題や問題の本質をつかみ、先を見据えた戦略策定と課題解決に繋がるSEOコンサルティング -

法人向けSEO研修企業のマーケティング担当者が第一線のプロからSEOを学べるリスキリングサービスです。
株式会社フルスピードは世界で60万人が導入する最高水準のSEO分析ツールAhrefsのオフィシャルパートナーでもあり、これまで培ってきたSEOノウハウとAhrefsのサイト分析力を活かしたSEOコンサルティングサービスをご提供することが可能です。SEOコンサルティングサービスの詳細に関しましては上記バナーをクリックしてご確認くださいませ。お気軽にご相談ください。
この記事を書いた人
記事の関連タグ






SEOの人気記事
-

なぜNAVERまとめはサービス終了したのか!?SEO視点で調べてみた
-

サーチコンソールの権限付与の方法を画像解説┃2025年最新
-

GA4とサーチコンソールの連携方法!メリット・確認方法・連携できない時の対処法まとめ
-

CLSとは? 低下要因と改善方法をわかりやすく解説
-

Googleサーチコンソールとは?設定~活用までの基礎を解説【2025年最新版】
SEOの新着記事
-

GoogleがAI検索に「優先ソース」を拡大!AI OverviewsとAIモードでお気に入りサイトが優先表示可能に!
-

GoogleがFAQリッチリザルトのサポートを終了!廃止スケジュール3段階と構造化データの扱いを解説
-

GoogleがAI OverviewsとAIモードのアップデートを発表!ウェブ探索を強化する5つの新機能を紹介!
-

低品質な外部リンクを受ける影響は?「無視する可能性がある」とジョン・ミューラー氏が回答
-

「戻るボタンで戻れない」のボタン不正操作行為に新しいスパム対策ポリシーを導入(Google)
関連タグから記事を探す