

検索エンジンとは?意味・仕組み・種類・シェアをわかりやすく解説【初心者向け】
Googleインデックス登録とは?意味や仕組み・リクエスト方法などを解説
公開日:2016年06月08日
最終更新日:2025年09月16日

当記事ではSEOに関わる「インデックス」について分かりやすく解説しています。
結論を先出ししますが、あなたが作ったコンテンツ(例えば、記事)はGoogleにインデックスされることで”初めてGoogle検索結果に表示させる”ことができます。Webサイト運営においてコンテンツがインデックスされることは非常に重要ですので、当記事にて「インデックスについての基本知識」を学習してみましょう。
↓【無料DL】「SEO内部対策チェックシート」を無料ダウンロードする
目次
検索エンジンの処理における「インデックス」とは
検索エンジンの処理における「インデックス」という言葉は、検索エンジンのデータベースにWebページのデータが格納されることを意味します。記事冒頭でお話しした通り、あなたがWeb上に公開したコンテンツは「インデックス」されて初めて”検索結果にコンテンツを表示”させることができるようになっています。
「インデックス」はプログラムやデータベースなどで使われる用語です。プログラムにおける「インデックス」という言葉は「配列の要素を指定するための通し番号」のことを指し、データベースにおいては「データベース内に格納されたデータを素早く検索して取り出すための索引データ」のことを指します(そもそも一般的に「インデックス」という言葉は「索引」「見出し」という意味があります)。
例えば、Google検索結果にあなたのコンテンツを表示させたい場合、Google検索エンジンのデータベースにコンテンツが格納される必要があります。ではどうやってGoogleにインデックスさせるのでしょう?次に「検索エンジンのインデックスの仕組み」についてご紹介します。
検索エンジンのインデックスの仕組み
検索エンジンがWebページをインデックスするためには、まずWebページの情報を収集する必要があるはずです。誰かがあなたが新しく公開したWebページの情報を収集しなければいけないのですが、ここで活躍するのが「クローラ」と呼ばれるWebページの情報を収集するためのプログラムです。
「クローラ」を動かすためにあなたがすべきことは何もありませんのでご安心ください(※とはいえ、あなたが”積極的に”クローラにWebページを「インデックス」するよう催促する方法は存在します。絶対に行わなければいけないアクションはないということをここでご理解ください)。
「クローラ」はWebサイト上を巡回しており、Web上に存在するWebページを順次確認し、「インデックス」作業を自動的に行ってくれます。クローラーが収集したWebページのデータは、Webページをインデックス化するためのプログラム「インデクサ」に渡されて処理され、データベースに登録されます。
収集したばかりのWebページのデータは、ページの内容を解析する際に不要なデータが含まれていたり、データの形式が揃っていなかったりしますので、インデクサによってその後の処理をしやすい形に変換されます。インデクサによってWebページは、ページ内のテキスト解析やリンクの解析などを行われ、各項目が指標化されます。
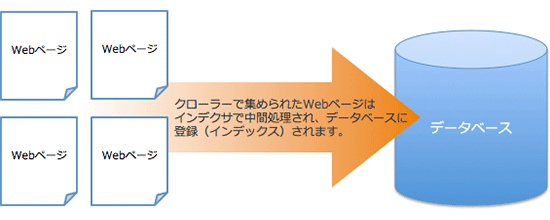
このような中間処理を行うことで、ランキング付けをする際に処理しやすい形式に変換できるだけでなく、検索エンジンのデータベースに格納されるデータ量も節約をすることができるので、インデックス化(インデクシングとも呼ぶ)は検索エンジンにとって非常に重要な工程だと言うことができます。
インデックスされることの意味
前述した通り、「あなたが公開したWebページ」が検索結果に表示されるためには、まず検索エンジンがそのWebページのデータを収集しデータベースに登録する必要があります。「インデックスされていないWebページ」は検索エンジンから見ると公開されていないWebページと同じ扱いを受けることとなるため、仮にそのWebページにどれほど素晴らしいコンテンツが書かれていても、どんな施策を行ったとしても、Webページがインデックスされていなければ、検索結果に表示されることはないということになります。
公開したWebページは、できるだけ早く検索エンジンにインデックスしてもらうことが”なるべく情報鮮度を落とさずWeb上に公開するという意味で重要”なのですが、例えば構造の複雑な大規模サイトや、階層が深くなってしまっているWebサイトでは、クローラが巡回し、該当Webページをクローリングする難易度が高くなり、なかなかインデックスされないということが起こりえます。
では、そういった「公開したWebページがなかなかクローラに見つけてもらえずインデックスされない状況」が起きてしまっている場合、どのように対処したらいいのでしょうか。
検索エンジンに公開したWebページを素早くインデックスしてもらう対策方法
現在の検索エンジンは非常に優秀なクローラーを持っていますので、公開したWebページの多くは、何もしなくてもインデックスされます。しかし、ドメインを取得したばかりの新しいWebサイトや、複雑なページ構成を持っている大規模サイトの場合には、なかなかインデックスされないこともあります。
そのような場合は以下2つの操作でWebページがインデックスされるようにアクションしてみて下さい。Googleなどの主要な検索エンジンでは、公開したWebページを素早くインデックスされやすくするためのツールなどを提供していますので、積極的に活用してみると良いです。
Googleサーチコンソールでインデックスをリクエストする方法
Googleサーチコンソールを利用すればGoogleにインデックスのリクエストを要求することができます。この方法が一番的確で無駄が少ないインデックスリクエスト手法です。Googleサーチコンソールを利用するためには、まずあなたのWebサイトとGoogleサーチコンソールを紐づける必要がありますが、その紐づけ作業が完了してしまえば簡単にサーチコンソールでインデックスリクエストを行うことが可能です。上記の解説URLからGoogleサーチコンソールをどのように操作してインデックスをリクエストすれば良いのかまとめていますのでチェックしてみましょう。
Googleサーチコンソールのサイトマップ送信でWebサイトの構造と存在を知らせる
2つ目の作業もGoogleサーチコンソールを利用したやり方です。1つ目のインデックスリクエストの方法は「Googleに直接的に公開したWebページのURLを知らせることでクローラの巡回優先度を高める」やり方でしたが、今回のサイトマップをGoogleに送信するやり方は、「Googleにあなたが運営しているWebサイトの構造を知らせる」やり方です。
あなたのWebサイトの情報が詰まったサイトマップを送信することで、Webサイトの輪郭がGoogleに伝わりやすくなり、結果的にスムーズなインデックス完了を促すことになります。インデックスを促せるだけでなく、Webサイトを運営しているとサイトマップを送信したほうが良いタイミングが定期的に訪れますので、こちらも操作手順を覚えておくと良いでしょう。
インデックス促進を促すための内部対策
Webページを検索エンジンに素早くインデックスしてもらうためには、サイトマップ送信やURL検査ツールだけでなく、内部施策も非常に重要です。具体的には以下のような対策が有効です。
内部リンクの最適化
Webサイト内の関連ページ同士を適切にリンクさせることで、クローラーが新しいページや更新ページを巡回しやすくなります。特にトップページやカテゴリページから深い階層のページにリンクを張ることで、クローラーが優先的に巡回できるようになります。
サイト構造の整理
サイトの階層構造やカテゴリの設計は、クロールの効率に大きく影響します。階層が浅く整理され、カテゴリごとにページが整理されていると、クローラーは効率的に巡回でき、インデックスされやすくなります。
外部リンク(被リンク)の活用
高品質な外部サイトからのリンクがあると、検索エンジンはそのページを重要と判断し、巡回優先度を上げることがあります。特に新規ページや更新頻度の高いページに対しては、信頼性のある外部サイトからのリンクがインデックス促進に役立つ場合があります。
Google検索結果画面で、簡易的にインデックス状況を確認する方法
Googleサーチコンソールを利用しなくても、Google検索結果でインデックスされているかを簡易的に確認する方法も存在します。それが「site:」もしくは「info:」を使ってWebページがインデックスされているか調べるやり方です。
実際にどうやるかと言いますと、以下のようなコマンドを検索ボックスに入力して検索するだけです。
info::そのページがインデックスされているか調べる
info:(調べたいWebページのURL)
site::指定したURLの配下にあるすべてのWebページインデックスを調べる
site:(調べたいWebページのURL)
「site:」コマンドは、指定したURL以下のページのインデックスの有無を調べることができる便利なコマンドですが、時々、本当はインデックスされているWebページが、結果ページに表示されないと言ったことがありますので、正確な情報を知りたい時は「info:」コマンドを利用しましょう。
noindexタグとインデックスされない原因に注意
<meta name=”robots” content=”noindex” />
noindexタグが埋め込まれたWebページは、検索結果に表示されません。これは、robots.txtという「検索エンジンのクローラーを制御するためのテキストファイル」を利用することで制御できます。
ただし、noindexという名前から「インデックスされない」と解釈されがちですが、実際にはクローラーはページを巡回して内容を確認し、インデックスに格納することがあります。外から見るとインデックスされていないように見えるだけです。重要なページに誤ってnoindexタグを設置しないよう注意しましょう。
また、noindexタグ以外にも、Webページがインデックスされない典型的な原因として以下があります。
- URLの重複やcanonicalの影響(同一または類似ページが多すぎる場合)
- robots.txtによるブロック
- ページ速度の遅さやクロール制限による巡回の遅延
- 低品質コンテンツやパラメータ付きURLの扱い
これらの原因を把握して対策することで、重要なページが正しく検索結果に表示されるようにしましょう。
まとめ
インデックスとは、公開したWebページの情報が検索エンジンのデータベースに登録されることを指します。インデックスされて初めて、検索結果にページが表示されるようになるため、Webサイト運営において非常に重要な工程です。クローラがページを巡回して情報を収集し、インデクサが解析・データベースに登録することで、検索ランキング付けが可能になります。また、公開したページを早くインデックスしてもらうためには、Googleサーチコンソールを使ったインデックスリクエストやサイトマップ送信、site:コマンドでの確認などの対策が有効です。なお、noindexタグが設定されているページは検索結果に表示されないため、重要なページには誤って設定しないよう注意が必要です。インデックスの仕組みを理解し、適切な対応を行うことで、あなたのWebサイトの検索結果での可視性を高めることができます。
よくわかる!Googleのインデックス登録に関するQ&Aまとめ
Q1. インデックスとは何ですか?
A. インデックスとは、Webページの情報が検索エンジンのデータベースに登録されることです。これにより、検索結果にページが表示されるようになります。
Q2. インデックスされないとどうなりますか?
A. インデックスされていないページは検索結果に表示されません。どれだけ良いコンテンツでも、検索からの流入は得られません。
Q3. インデックスを早く促す方法は?
A. GoogleサーチコンソールでURL検査ツールを使う、サイトマップを送信する、site:やinfo:コマンドで状況確認などの方法があります。
Q4. noindexタグとインデックスの関係は?
A. noindexタグがあるページは、クローラが確認しても検索結果には表示されません。重要なページには誤って設定しないことが重要です。
Q5. 自動的にインデックスされる場合もありますか?
A. はい、多くのWebページはクローラによって自動的にインデックスされます。ただし、新しいサイトや複雑な構造のサイトは手動で促すとより早く反映されます。
株式会社フルスピードのSEO関連サービスのご紹介
-

Webサイト
コンサルティングSEO、コンテンツSEO、UIUXの三軸でアプローチし、流入数・コンバージョンをアップさせます。 -

SEOコンサルティングサイト課題や問題の本質をつかみ、先を見据えた戦略策定と課題解決に繋がるSEOコンサルティング -

法人向けSEO研修企業のマーケティング担当者が第一線のプロからSEOを学べるリスキリングサービスです。
株式会社フルスピードは世界で60万人が導入する最高水準のSEO分析ツールAhrefsのオフィシャルパートナーでもあり、これまで培ってきたSEOノウハウとAhrefsのサイト分析力を活かしたSEOコンサルティングサービスをご提供することが可能です。SEOコンサルティングサービスの詳細に関しましては上記バナーをクリックしてご確認くださいませ。お気軽にご相談ください。
この記事を書いた人
記事の関連タグ






SEOの人気記事
-

なぜNAVERまとめはサービス終了したのか!?SEO視点で調べてみた
-

サーチコンソールの権限付与の方法を画像解説┃2025年最新
-

GA4とサーチコンソールの連携方法!メリット・確認方法・連携できない時の対処法まとめ
-

CLSとは? 低下要因と改善方法をわかりやすく解説
-

Googleサーチコンソールとは?設定~活用までの基礎を解説【2025年最新版】
SEOの新着記事
-

GoogleがAI検索に「優先ソース」を拡大!AI OverviewsとAIモードでお気に入りサイトが優先表示可能に!
-

GoogleがFAQリッチリザルトのサポートを終了!廃止スケジュール3段階と構造化データの扱いを解説
-

GoogleがAI OverviewsとAIモードのアップデートを発表!ウェブ探索を強化する5つの新機能を紹介!
-

低品質な外部リンクを受ける影響は?「無視する可能性がある」とジョン・ミューラー氏が回答
-

「戻るボタンで戻れない」のボタン不正操作行為に新しいスパム対策ポリシーを導入(Google)
関連タグから記事を探す