
Google注目のアルゴリズム:オーサーランクの特許「Agent Rank(エージェント・ランク)」をご紹介します。
robots.txtとは
公開日:2016年06月08日
最終更新日:2025年01月31日

robots.txtとは、検索エンジンに代表されるクローラーを制御するためのテキストファイルのことです。ただのテキストファイルなので、メモ帳などのテキストエディタで作成することができ、特別なアプリケーションを使う必要はありません。テキストエディタでrobots.txtを作成したら、ドメインのルートディレクトリ(一番上の階層)にアップロードして公開します。
↓【無料DL】「SEO内部対策チェックシート」を無料ダウンロードする
目次
robots.txtの役割・使用目的
robots.txtは、主に特定のファイルやディレクトリへのクロールを制限する目的で使用されます。また、サイトマップファイルの格納場所をクローラーに伝える役割も持っています。
検索エンジンのクローラーをrobots.txtでブロックすることで、そのURLを検索結果に表示させないようにすることが可能です。
ただし、そのURLに他のWebサイトからリンクが張られていたり、検索エンジンが重要なURLだと判断している場合には、仮にrobots.txtでクロールをブロックしたとしても、検索結果に表示されてしまう場合があります。

上図のように、robots.txtで指定したとしても完全に検索結果に表示させないようにすることは不可能です。
さらに、robots.txtに書いたクローラーへの指示は強制力を持ったものではありませんので、いわゆる「お行儀の悪いクローラー」の場合はrobots.txtの指示を無視することもあります。
顧客に関する情報など、本当に重要な情報を掲載しているURLを公開しなくてはいけない場合には、robots.txtでクロールを制限するだけでなく、パスワードによる認証やアクセスできるIPアドレスを制限するなどのセキュリティ対策を併用しましょう。
robots.txtの注意点
robots.txtを使う上で注意しなくてはいけない点がいくつかありますので解説します。
不用意に使うとセキュリティリスクになる
robots.txtはルートディレクトリに「robots.txt」という名前で公開する必要があり、このファイルは誰でも閲覧することが可能です。
例えば、こちらはGoogleのrobots.txt(https://www.google.co.jp/robots.txt)、こちらはみずほ銀行のrobots.txt(http://www.mizuhobank.co.jp/robots.txt)です。
先ほどご説明した通り、robots.txtにはクロールして欲しくないURL、検索エンジンのクローラーであれば検索結果に表示して欲しくないURLを指定するものですので、「このURLは秘密のURLですよ」と教えているようなものです。
仮にrobots.txtに、Webサイトを管理する画面のURLや重要な情報が掲載されたURLが指定されていたらどうなるでしょうか。
非常に危険なことはお分かり頂けると思います。
先ほども書きましたが、本当に重要なページにはパスワード認証やIP制限など、不正アクセスを防止するセキュリティ対策を万全にしておく必要があります。
noindexタグとの併用時の注意
noindexタグは、タグを設置したページを検索結果に表示しないようにするためのタグです。検索結果に表示される状態のページにnoindexタグを設置すると、そのページは検索結果に表示されなくなります。
しかし、robots.txtでnoindexタグを設置したURLへのクロールをブロックしてしまうと、検索エンジンはnoindexタグを認識できず、いつまで経っても検索結果に表示される状態が続いてしまいます。
noindexタグを設置したURLを検索結果から消したい場合には、クローラーは自由にアクセスできるようにしておきましょう。
画像やスクリプトなどを不用意にブロックしない
現在のGoogleは、HTMLページに使用されている画像ファイルやスクリプトも一緒に読み込んでページの内容を判断することがあります。
もしそういった場合にGoogleのクローラーが画像などにアクセスできない場合、ページの内容が判断しにくくなってしまう場合がありますので、ページで使用している画像やスクリプトはrobots.txtでブロックしないようにする方がいいでしょう。
robots.txtの書き方
robots.txtは非常にシンプルな構造になっています。
「対象としたいクローラーのユーザーエージェントを指定」し、「クロールを拒否したいURLを指定」するだけです。
ユーザーエージェントを指定する
robots.txtでユーザーエージェントを指定すると、指定されたユーザーエージェントでアクセスしたクローラーが指示の対象になります。
「Google画像検索用のクローラーだけ」、「Bingのクローラーだけ」というように対象となるクローラーを絞り込むことが可能ですが、一般的にはすべてのクローラーを対象にする*(アスタリスク)を指定します。
書式
User-agent:(対象にしたいクローラーを指定)
例文
すべてのクローラーを対象にする場合
User-agent:*
Bingのみを対象にする場合
User-agent:bingbot
代表的なクローラーのユーザーエージェントは、こちらのサイトで確認することができます。(http://www.robotstxt.org/db.html)
クロールを拒否したいURLの指定
クロールを拒否したいURLを「Disallow:」で指定します。ディレクトリを指定した場合には、そのディレクトリ以下の階層のすべてのURLが対象になります。
書式
Disallow:(クロールを拒否したいURLを指定)
例文
dir-01という名前のディレクトリ以下のURLを指定する場合
Disallow: /dir-01/
パターンマッチングも使えますので、特定のディレクトリ内のjpgファイルのみアクセスを拒否するという設定も可能です。
例文
/dir-01/img/内のjpgファイルを指定する場合
Disallow: /dir-01/img/*.jpg$
*(アスタリスク)は1文字以上の文字を表します。上記のように設定した場合、「a.jpg」も「b.jpg」も対象に含まれます。
$(ドル記号)は、末尾のマッチングを表します。上記の場合「.jpg」で終わるURLがすべて対象になります。
また、Googleのクローラーは大文字と小文字を区別しますので、「a.jpg」と「a.JPG」は別のURLとして処理されます。
特定のURLだけクロールを許可したい場合
Disallowを使ってクロールを拒否したURLのうちで、一部のURLはアクセスを許可したいということもあると思います。
その場合には、クロールを許可するURLを「Allow」で指定します。
書式
Allow:(クロールを許可したいURLを指定)
例文
/dir-01/ディレクトリのうち、001.htmlのみクロールを許可したい場合
Disallow: /dir-01/
Allow: /dir-01/001.html
サイトマップのURLを指定
サイトマップファイルのURLをクローラーに伝えるためには、robots.txtに以下のように記述します。
書式
Sitemap:(サイトマップファイルのURLを指定)
例文
Sitemap:http://example.com/sitemap.xml
robots.txtの構文エラーをチェックする方法
robots.txtの構文エラーのチェックは、SearchConsoleのrobots.txtテスターを使うと簡単です。robots.txtに書いた内容をコピー&ペーストするだけで構文エラーがないかどうかをチェックしてくれます。
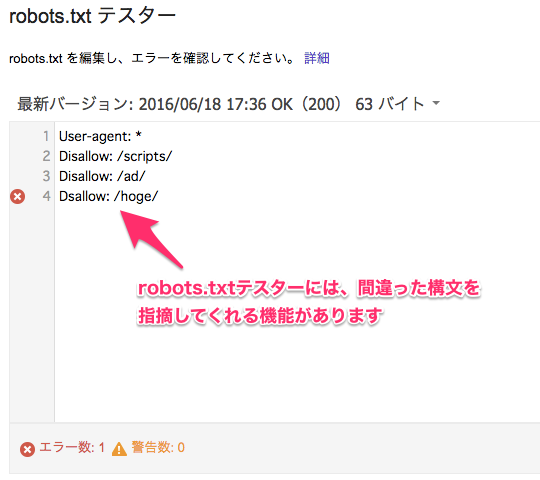
本番サーバーにrobots.txtを公開する前に、構文エラーがないかどうか確認しておきましょう。
株式会社フルスピードのSEO関連サービスのご紹介
-

Webサイト
コンサルティングSEO、コンテンツSEO、UIUXの三軸でアプローチし、流入数・コンバージョンをアップさせます。 -

SEOコンサルティングサイト課題や問題の本質をつかみ、先を見据えた戦略策定と課題解決に繋がるSEOコンサルティング -

法人向けSEO研修企業のマーケティング担当者が第一線のプロからSEOを学べるリスキリングサービスです。
株式会社フルスピードは世界で60万人が導入する最高水準のSEO分析ツールAhrefsのオフィシャルパートナーでもあり、これまで培ってきたSEOノウハウとAhrefsのサイト分析力を活かしたSEOコンサルティングサービスをご提供することが可能です。SEOコンサルティングサービスの詳細に関しましては上記バナーをクリックしてご確認くださいませ。お気軽にご相談ください。
この記事を書いた人
記事の関連タグ






SEOの人気記事
-

なぜNAVERまとめはサービス終了したのか!?SEO視点で調べてみた
-

サーチコンソールの権限付与の方法を画像解説┃2025年最新
-

GA4とサーチコンソールの連携方法!メリット・確認方法・連携できない時の対処法まとめ
-

CLSとは? 低下要因と改善方法をわかりやすく解説
-

Googleサーチコンソールとは?設定~活用までの基礎を解説【2025年最新版】
SEOの新着記事
-

GoogleがAI検索に「優先ソース」を拡大!AI OverviewsとAIモードでお気に入りサイトが優先表示可能に!
-

GoogleがFAQリッチリザルトのサポートを終了!廃止スケジュール3段階と構造化データの扱いを解説
-

GoogleがAI OverviewsとAIモードのアップデートを発表!ウェブ探索を強化する5つの新機能を紹介!
-

低品質な外部リンクを受ける影響は?「無視する可能性がある」とジョン・ミューラー氏が回答
-

「戻るボタンで戻れない」のボタン不正操作行為に新しいスパム対策ポリシーを導入(Google)
関連タグから記事を探す