
CSSのclass名はSEOに直接効果がないとGoogleが発表
Googlebotの2MBクロール制限|ページ容量の確認方法と上限を超えてしまう書き方
公開日:2026年04月14日

この記事を読むと理解できること
●Googlebotのクロール上限が2MBであることをGoogleエンジニアが語っている背景が分かる
●公式ドキュメントに「2MB」と明記されるまでの経緯が分かる
●Googlebotの2MBクロール制限|ページ容量の確認方法3つが分かる
●2MBクロール制限に引っかかるリスクがあるHTMLの書き方が分かる
●公式ドキュメントに「2MB」と明記されるまでの経緯が分かる
●Googlebotの2MBクロール制限|ページ容量の確認方法3つが分かる
●2MBクロール制限に引っかかるリスクがあるHTMLの書き方が分かる
GoogleエンジニアのGary Illyes(ゲイリー・イリーズ)は、Google公式ポッドキャスト「Search Off the Record」の中で、GooglebotのHTMLクロール上限が2MBであることを明らかにしています。長らくGoogleの公式ドキュメントには「15MB」と記載されていましたが、2026年2月に誤記が修正され、正式に「2MB」と明記されました。
当記事では、「Googlebotの2MBクロール制限の背景・ページ容量の確認方法・上限を超えてしまうHTMLの書き方」について解説します。
↓【無料DL】「SEO内部対策チェックシート」を無料ダウンロードする
目次
Googlebotのクロール制限は2MBだとGoogleエンジニアが語る
Search Off the Recordでゲイリー・イリーズが実際に語っている様子
引用:Google crawlers behind the scenes
上記YouTube「クローリングの裏側」の日本語全文翻訳を読む(※長文です)
Google Search Off the Record: クローリングの裏側
(00:02) マーティン: こんにちは。「Search Off the Record」の最新エピソードへようこそ。この番組では、Googleの検索関係チームの私たちが、舞台裏で何が起きているのかを皆さんにお見せしようとしています。今日はゲイリーが一緒です。こんにちは、ゲイリー。
ゲイリー: やあ、調子はどうだい?
マーティン: 最高だよ。
ゲイリー: 素晴らしいね。じゃあ、その気分を変えてやろう。
(00:35) ゲイリー: クローリングについて話したいんだ。
マーティン: おっと、勘弁してくれよ。
ゲイリー: いや、実はクローラーについて話したいんだ。私たちのクローリング・インフラが具体的にどうなっているのか、これまで詳しく話したことがあったかなと思ってね。みんなGooglebotのことを、まるで生き物か、あるいは特定のプログラムかのように話すだろ。
(01:00) ゲイリー: でも、ダブルクリックしたら起動する「Googlebot.exe」なんてものは存在しないよね?
マーティン: ないね。
ゲイリー: 仕組みはちょっと違うんだ。
マーティン: 何だって? それを教えてくれたのは君じゃないか。
ゲイリー: まあ、その通りだ。
マーティン: 少し詳しく説明しようか。Googlebotをどうイメージすればいい? クローリング・インフラは大体どんな感じなんだい?
ゲイリー: 「Googlebot」と呼ぶのは実は誤用なんだ。2000年代初頭の初期の頃なら、それでも良かった。当時はプロダクトが1つで、クローラーもおそらく1つだったから。でも、すぐに別のプロダクトが出てきた。たしかAdWords(現Google広告)だったかな。それからクローラーが増え、プロダクトが増えるたびに、さらにクローラーが増えていった。
(01:31) ゲイリー: でも「Googlebot」という名前がなぜか定着してしまった。一般的にクローリング・インフラ全体について話すとき、私たちはそれをGooglebotと呼ぶ傾向があったんだ。
(02:03) ゲイリー: だけど、それはひどく不正確だ。Googlebotは、クローラー・インフラと通信している「一つのもの」に過ぎなかったんだから。これで意味が通じるかな?
マーティン: どうイメージすればいいんだ?「クローラー・インフラと通信している」ってどういう意味だい? Googlebotこそがクローラー・インフラそのものじゃないのか?
ゲイリー: いや、この3分間ずっと言っているじゃないか。
(02:24) マーティン: ああ、でもまだ絵が浮かばないんだ。
ゲイリー: だから、Googlebotは私たちのクローラー・インフラそのものではないんだ。私たちのクローラー・インフラには外部向けの名前はない。内部的な名前はあるけどね。名前は何でもいい、仮に「ジャック」と呼ぼう。
ゲイリー: それは……何て言えばいいかな、いわば「Software as a Service(SaaS)」なんだ。
マーティン: おお、なるほど。
(02:43) マーティン: SaaSだね。
ゲイリー: そう。そして「ジャック」にはAPIエンドポイントがある。そのAPIエンドポイントを呼び出すことで、インターネットからデータを取得(フェッチ)できるんだ。
マーティン: ふむふむ。
ゲイリー: APIを呼び出すときは、いくつかのパラメータを指定する必要がある。例えば「データが返ってくるまでどれくらい待つか」「送信するユーザーエージェントは何にするか」「どのrobots.txtのトークンに従うか」といったことだ。
(03:35) ゲイリー: ほとんどのものにはデフォルト値が設定されているから、通常は省略できる。それで呼び出しが簡単になっているわけだけど。基本的には、クラウドやどこかのデータセンターにある何かに対する「APIコール」に過ぎない。それが君の代わりにフェッチを実行してくれるんだ。
マーティン: ソフトウェア開発者やプロダクト担当者にとっては、すごく便利だね。
(04:00) マーティン: それを管理するチームもいるんだろうね。実質的に、私は誰かに「代わりに全部決めてくれ」とアウトソーシングしているようなものだから。
ゲイリー: そうだね。このプロダクト――内部向けであっても今はプロダクトと呼べるけど――は、もう[鼻を鳴らす]ものすごく、ものすごく長い間存在している。技術的にはGoogleが誕生した時からあるんだ。
(04:18) ゲイリー: 変化はあったけどね。初期のバージョンは、どこかのエンジニアのワークステーションで動いている「wget」みたいなものだったから。1998年か99年頃の話だ[笑]。プロダクトが増えるにつれて、より多くの人員やリソースが必要になり、当然、各チームがこのサービスを呼び出せるようにアーキテクチャを再構築する必要があった。でも本質的には、ずっと同じことをしている。
(05:04) ゲイリー: つまり、「インターネットを壊さずに、インターネットから何かを取ってこい」と命令すれば、サイト側の制限が許す限りそれを実行してくれる。一言で言えば、そういうことだ。
マーティン: なるほど。基本的には、設定の束を渡すわけだね。「このURLの束をクロールしてくれ」というのも設定の一部で、それをサービスに渡すと、何かが返ってくると。
ゲイリー: そう、そんな感じだ。
(05:40) マーティン: その「何か」はおそらくHTTPレスポンスやヘッダー、ボディ、そして追加のメタデータだろうね。いいじゃないか。つまり、Googlebotというのは、私が渡す設定の断片、というか単なる「設定の名前」なんだね。
ゲイリー: もう一度言ってくれ。
マーティン: つまり、Googlebotはプログラムではなくて、私が渡す設定の一部なんだろう? 設定に付けられた「名前」のような。
(06:02) ゲイリー: まあ、それはSaaSを呼び出す「クライアント(呼び出し側)」の一つだね。
マーティン: なるほど。設定の一部ですらないんだ。ある特定のチームが、中央サービスに送るフェッチのリクエストに使っている名前に過ぎないんだね。
ゲイリー: つまりクライアントの一つだ。
マーティン: まさにクライアントだ。
ゲイリー: その通り。
(06:23) マーティン: ということは、他にもクライアントがいるってことだよね。
ゲイリー: もちろん。主要なものはドキュメントにまとめているけど、Googleは巨大な会社だから、インターネットからデータを取得したいチームはたくさんある。だからクローラーもたくさんあるし、名前の付いたクローラーもたくさんある。
(06:53) ゲイリー: つまり、数十、下手をすれば数百の異なるクローラーや特別なフェッチャーを文書化しなきゃいけないことになる。でも、シンプルなHTMLページ(開発者向けドキュメント)でそれをやるのは不可能だ。だから、どこかで線を引く必要がある。クローラーの規模が本当に小さい、つまりインターネットからあまり取得しないようなら、ドキュメントには載せないようにしている。 developers.google.com の掲載スペースは貴重だからね。
(07:17) マーティン: 将来的には違う扱いにするかもしれないけど、今はスペースの都合で、主要なクローラーや特別なフェッチャーだけを載せているんだね。……ところで「フェッチャー(fetcher)」と「クローラー(crawler)」と言ったけど、違いは何だい?
ゲイリー: 一番簡単な説明は、クローラーは「バッチ」で仕事をし、フェッチャーは「個別のURL単位」で仕事をするということだ。
(07:50) ゲイリー: つまり、フェッチャーにURLを渡すと、その1つのURLだけを取ってくる。URLのリストを渡してフェッチさせることはできない。
マーティン: なるほど。
ゲイリー: クローラーの場合は、通常URLが絶え間なく流れ込んできて、チームのためにインターネットから継続的に取得し続ける。あと内部的なポリシーとして、フェッチャーは何らかの形で「ユーザーが制御するもの」である必要がある。
(08:21) ゲイリー: つまり、反対側でレスポンスを待っている人間がいるということだ。
マーティン: なるほど。クローラーは「時間がある時にやっておいて」という感じだね。
ゲイリー: そう。
マーティン: ああ、なるほど。自動化されたシステムがレスポンスを受け取って処理するのと、誰かがボタンをクリックして結果を待っているのとでは、確かに対処の仕方が変わるね。
(08:44) マーティン: 分かった。それがフェッチャーとクローラーの違いなんだね。
ゲイリー: そう思うよ。他にも違いはあるはずだけどね。例えば、フェッチ元のIPアドレスの範囲が違ったり。
マーティン: ああ。
ゲイリー: でもそれ以外は、ほぼ同じインフラを使って、同じタスクを違うやり方で実行しているだけだ。
(09:25) マーティン: 主要なクローラーやフェッチャーがドキュメント化されていれば、人々はそれを知ることができる。でも、君は主要なものしか載せないと言ったよね。もし私が新しいプロジェクトを始めて、ユーザーにURLを入力させてボタンをクリックさせる機能を作ったとしたら、その規模が小さければドキュメントには載らないってことだよね?
ゲイリー: その通り。
マーティン: なるほど。
(09:46) ゲイリー: 文書化するかどうかの基準については、実は私がかなりの時間を費やして、内部でアラートを飛ばすためのSQLクエリのようなものを作ったんだ。あるクローラーやフェッチャーが1日あたりのフェッチ数のしきい値を超えたときにアラートが出る。
(10:19) ゲイリー: アラートが出ると、内部で「新しい大型クローラーが現れたぞ。文書化すべきか検討せよ」という課題(チケット)が作成される。それで私たちは、そのクローラーの特性や目的を調べに行く。チームに確認して、誤って何かをしていないかもチェックする。
(10:53) ゲイリー: 過去には、サイトからクローラーについての苦情が来たことがあった。チームに確認したら「いや、そのクローラーは2年前に終了したはずだ。ありえない」と言うんだ。でもログを見ると、確かにフェッチしている。突き止めると、プロジェクトが終わったときに誰かが停止し忘れたジョブがあって、それが理由もなくインターネットからデータを取得し続けていたんだ。
(11:21) ゲイリー: 今ではそんなことは稀だよ。モニタリングやチェック体制が整っているからね。フェッチやクロールが内部的に本当に役に立っているかを確認している。
マーティン: なるほど。ただ闇雲に取ってくるわけじゃないんだね。
ゲイリー: その通り。あと、役立つという点で言うと、内部的にはかなり強力なキャッシュ機能がある。これはHTTPのキャッシュメカニズムとは別のものだ。例えば、Googleニュースが10秒前に何かをフェッチしたとする。その時、ウェブ検索のデータを供給している別のクローラーが同じものをまた取りに行く必要があるか? おそらくない。
(11:54) ゲイリー: だから、10秒前に取得したコピーを渡して、無駄な通信を避けるんだ。ただ、プロジェクトごとに「他の目的で取得されたコンテンツを再利用できるか」というポリシーが違ったりもするから、そこはトリッキーだね。
(12:18) ゲイリー: 例えば、AdWordsはウェブ検索用に取得されたコンテンツを再利用できない、といった具合に。
マーティン: 筋が通っているね。さっき「停止し忘れたジョブ」の話があったけど、このインフラは巨大で、毎日大量のURLを処理しているはずだ。まさか君のデスクにあるコンピュータで動かしているわけじゃないよね?
(12:48) ゲイリー: インフラの話になるけど、Google Cloudの実行インスタンス(ランナー)のようなものを想像してくれ。それと似たようなものが内部にもあるんだ。アトランタにあるデータセンターのリモートサーバーでジョブを立ち上げたりできる。C++で書いたプログラムをバイナリにして、そこで動かすんだ。
(13:18) ゲイリー: そのコンパイルしたプログラムの中から、APIコールを行う。そのプログラムからSaaSのクローラー・インフラのエンドポイントにアクセスして、クロールの設定や指示を出すんだ。
マーティン: それは手動でやるのかい? それとも、例えばジオブロック(地域制限)されている場合に、適切なアクセスポイントを賢くスケジュールしてくれるのかい?
(13:44) ゲイリー: おっと、それは私の気になるテーマだね。ジオブロックは面白いよ。実は一般的に、私たちはそれに対処するためのインフラを持っていないんだ。私たちの典型的なIPアドレス(66.129…で始まるようなもの)は、国籍がUS(米国)として割り当てられている。
(14:17) マーティン: ふむ。
ゲイリー: 詳しく調べればカリフォルニア州マウンテンビューになる。だからドキュメントにも「通常は米国からクローリングしている」と書いてあるんだ。誰かがジオブロックをかけていれば、私たちのクローラーはカリフォルニアのIPとして扱われるから。
マーティン: うん。
ゲイリー: フェッチできなくなる。403エラーが出るか、接続タイムアウトのようなネットワークエラーになるだろうね。特定の地域以外からのリクエストを遮断するファイアウォールがあれば、コネクションは切断され、応答すら返ってこない。
(14:57) ゲイリー: これに対処する方法としては、私たちのIPプールの中から別の国の場所が設定されているIPを探し出し、それをクローリング・インフラ用にリースすることだ。でも、これらのアクセスポイントは大容量のクローリング用には設計されていない。だから、例えばルーマニアやドイツ、スイスにいる全員のクロールを処理できるほどのキャパシティはないんだ。
(15:33) ゲイリー: まあ、スイスは小さいからいけるかもしれないけどね[笑]。だから、それらのIPアドレスを割り当てるのにはすごく慎重だよ。技術的には可能だし、コンテンツの有用性が非常に高いと分かっていれば、時々そうすることもある。
(16:02) ゲイリー: あまりいい例じゃないけど、例えば「青い目のマーティン」を検索する人が十分たくさんいたとしよう。
マーティン: おっと、何だって。
ゲイリー: 私の目の色の話がまた出てきたね。
マーティン: そんな話、普通出てこないだろ。
ゲイリー: とにかく、誰かが「青い目のマーティン」を探していて、そのコンテンツがドイツのサイトにあると分かっている場合。もしそのサイトが国外を遮断していれば、ドイツからアクセスしてコンテンツを取得しようと努力するかもしれない。
(16:29) ゲイリー: まあ、これは悪い例だから引用しないでくれよ。私のマネージャーのジョン・ミューラーが言ったことにしておいてくれ。でも理論上はそう動く。
マーティン: 分かった。
ゲイリー: でも、これをアテにするのは本当に、本当に、本当に悪いアイデアだ。
マーティン: つまり、Googlebotに確実に来てほしければ、ジオブロックはするなということだね。
ゲイリー: そういうことだ。
(16:51) マーティン: なるほど。もう一つ思いついたんだけど、ジオブロックをする人もいる一方で、クローラーは大量のトラフィックを発生させるよね。私たち側で、行動ルールやベストプラクティスのようなものはあるのかい? 「Googleクローリング・インフラさん、この設定で1時間ごとに何十億ものURLをクロールして」と言ったら、そのままやってしまうのか、それとも振る舞いについてのガイダンスがあるのか? インターネットを圧倒してしまう可能性があるだろ。
(17:21) ゲイリー: それはインフラレベルで処理されているよ。
マーティン: ふむ。
ゲイリー: 実際、インフラを共通化している理由の一つがそれだ。各チームがインターネットを壊さないように強制する必要があるからね。例えば、私が新米エンジニアだとする。
(17:58) ゲイリー: Googleに入社して、データセンターのサーバーにアクセスし、シェルスクリプトを書いてソケットを開き、データをストリーミングし始めたとする。
ゲイリー: そのサーバーには10Gbpsの接続がある。 martin-split.com (マーティンのサイト)に行って、毎秒10GBでデータを流し込み始めたら、君のサーバーやホスティング会社は喜ばないだろう?
(18:20) マーティン: そうだね。
ゲイリー: だから代わりに、データセンターのサーバーから直接外部へアクセスすることは原則できないようになっている。クローラー・インフラのエンドポイントを呼び出さない限りね。
(18:59) ゲイリー: クローラー・インフラ側では、例えば martin-split.com への繰り返しのフェッチで接続時間がどんどん長くなっていったら、速度を落とさなきゃいけないと判断し、リクエストを絞る(スロットリング)。503レスポンスが返ってきたら、サーバーが何らかの形で圧倒されている可能性が高いから、さらに速度を落とす。
(19:31) ゲイリー: でも、403や404は関係ない。それは単なるクライアントエラーだからね。間違ったURLを送ったとか。だから「インターネットを壊さないでください」という部分はインフラレベルで組み込まれていて、個別のチームがコントロールできることじゃないんだ。
マーティン: 自分のプロジェクトで大失敗する心配はないわけだね。それは安心だ。他にもインフラが規定している一般的なガイドラインはあるかい?
(19:53) ゲイリー: 私たちのインフラを守るためのものはいくつかある。例えば、有名な「デフォルト15MB制限」だ。これはインフラレベルで設定されていて、設定を上書きしないクローラーはすべて15MBの制限がかかる。
(20:29) ゲイリー: サーバーからデータを受け取り始めて、内部のカウンターが15MBに達したら、データの受信を停止するんだ。コネクションを切断するかどうかは分からないけど、サーバーに「もう十分だ、止めていいよ」と伝える。
ゲイリー: ただし、個別のチームがこれを上書きすることは可能で、実際よく行われている。例えば「Google検索」の場合、この制限は上書きされている。
(20:50) ゲイリー: 通常は2MBに制限されているんだ。
マーティン: 全部?
ゲイリー: ほとんどすべてだね。例えばPDFなら64MBとかかな。
マーティン: PDFは大きくなるからね。HTTP標準をPDFとして書き出すと96MBくらいになるとか言ってなかったっけ?
(21:29) マーティン: 多分ね。すごく大きかったのを覚えている。
ゲイリー: 全部フェッチしてHTMLに変換して……なんてやっていたらインフラがパンクしてしまう。データが多すぎるんだ。HTMLも同じだ。HTMLのリビングスタンダード(仕様書)みたいに14MBもあるページは、丸ごとはフェッチしない。幸い、彼らは機能ごとに個別のページを用意してくれているから、そっちをフェッチすればいい。14MBもある1枚の巨大なページからは、有益な情報は得られないんだ。
(22:15) マーティン: そうだね。
ゲイリー: 他のクローラーのことは詳しくないけど、きっと違う設定になっているはずだ。同じプロジェクト内でも、目的によって設定を変えることもあるだろうしね。例えば、何かをものすごく速くインデックスする必要があるなら、制限を1MBにするとか。
(22:42) ゲイリー: 実際にそうかは知らないけど、ありえる話だ。数秒以内にインデックス作成パイプラインを通さなきゃいけないなら、データは少ないほうが扱いやすいからね。
マーティン: 確かに。クローリングを単一の塊(モノリス)としてではなく、理解し直すのは有益だね。
(23:04) マーティン: それはむしろ「SaaS」であり、ウェブ検索はそのクライアントの一つに過ぎない。設定は変えられるし、Googlebotの中でも変えられる。画像を探しているなら、2MBより大きく設定しているだろうし、PDFならドキュメント通り64MBだろうし。
(23:29) マーティン: リンクは貼っておくよ。でも、多くのパラメータを指定して呼び出す「サービス」だと考えれば、リクエストレベルで設定が変わることも納得がいく。「Googlebotは常に一定だ」というわけじゃないんだね。わお、すごいな。
ゲイリー: かなりの情報量だったね。
(23:55) マーティン: ああ、盛りだくさんだった。でも有益だったと思うし、リスナーもそう思ってくれるといいな。こういう話をもっと聞きたいか、役に立ったかどうか、下のコメント欄で教えてほしい。番組の登録も忘れずに、また次回。ゲイリー、今日はありがとう。
ゲイリー: 君は警察か?
マーティン: 警察じゃないよ。
ゲイリー: なら、人様の生き方に口を出すなよ(「番組登録しろ」などの呼びかけに対して)。
マーティン: 提案しているだけじゃないか。まったく……。
ゲイリー: 失礼なやつだ。
マーティン: はいはい。
ゲイリー: じゃあな。
マーティン: はいはい、さよなら。
(24:44) マーティン(ナレーション): ポッドキャストを楽しんでいただけましたか。リスナーの皆さんにとっても、面白く、洞察に満ちた内容であれば幸いです。LinkedInでメッセージをくれたり、次のイベントで話しかけてくれたりするのを待っています。考えがあれば教えてください。そしてもちろん、高評価とチャンネル登録をお忘れなく。ご視聴ありがとうございました。さようなら。
「Search Off the Record」はGoogleの検索関連チームが検索の舞台裏を語る公式ポッドキャストです。本記事で紹介する内容は、上記のYouTube録画内容である「GoogleエンジニアのGary Illyes(ゲイリー・イリーズ)とMartinによるクローリング回の内容」をもとにしています。なお、動画は英語のみで日本語字幕は存在しないため、以下では会話の要点を日本語に翻訳して紹介します。
Googlebotはクローラー共通インフラの「いちクライアント」に過ぎない
ゲイリーはポッドキャストの中で、「Googlebot.exeのような単一のプログラムは存在しない」と明言しています。Googleのクローリングの実態は、社内で「SaaS」として機能する共通インフラであり、APIエンドポイントを呼び出すことでインターネット上のデータを取得する仕組みになっているようです。
GooglebotはそのAPIを利用する「クライアントの一つ」に過ぎず、Google広告やGoogleニュースなど、データ取得が必要なチームはそれぞれ独自のクライアントとしてこのインフラを利用しています。
Google検索チームがインフラデフォルトのクロール上限15MBを2MBに上書きしている
共通インフラのデフォルトのクロール上限は15MBに設定されているようです。ゲイリーの説明によれば、各チームはこの上限を独自に上書きできる仕様になっており、Google検索チームはGooglebotの上限を2MBに設定しているとのことです。
PDFについては別途大きめの上限が設けられており、公式ドキュメントでは64MBと明記されています。また、HTMLで参照されるCSSやJavaScriptなどの各リソースは個別に取得され、それぞれに同じファイルサイズの制限が適用されます。
GooglebotのHTMLクロール上限が2MBと公式ドキュメントに明記されるまでの経緯
Google公式ドキュメントのクロール上限の誤記が現場からの報告をきっかけに発覚
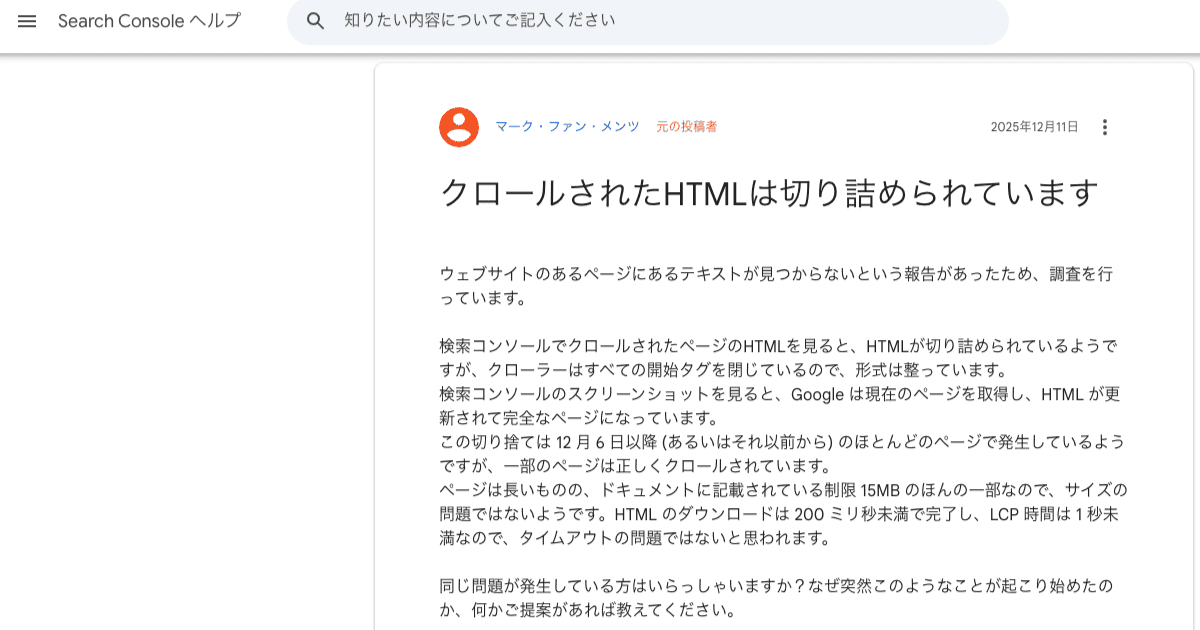
引用:クロールされたHTMLは切り詰められています(Search Console ヘルプ)
2025年12月、あるサイト運営者がGoogleサポートフォーラムに「ページのテキストが検索にインデックスされない。HTMLは切り詰められているようだが、ドキュメントに記載の15MB制限にはほど遠いサイズのはず」と報告しました。
Googleの公式ドキュメントには長らく「GooglebotはHTMLファイルの最初の15MBをクロールできる」と記載されていました。これはクローラー共通インフラのデフォルト値である15MBをそのままGooglebotの上限として説明してしまったものと考えられており、Googlebotに個別設定されている2MBという実際の上限とは異なる内容だったようです。共通インフラのデフォルト上限とGooglebotの個別上限を区別せずに記述していたことが、誤記の原因とみられています。
「クロール上限2MBの実態」に合わせてGoogle公式ドキュメントの記述を修正
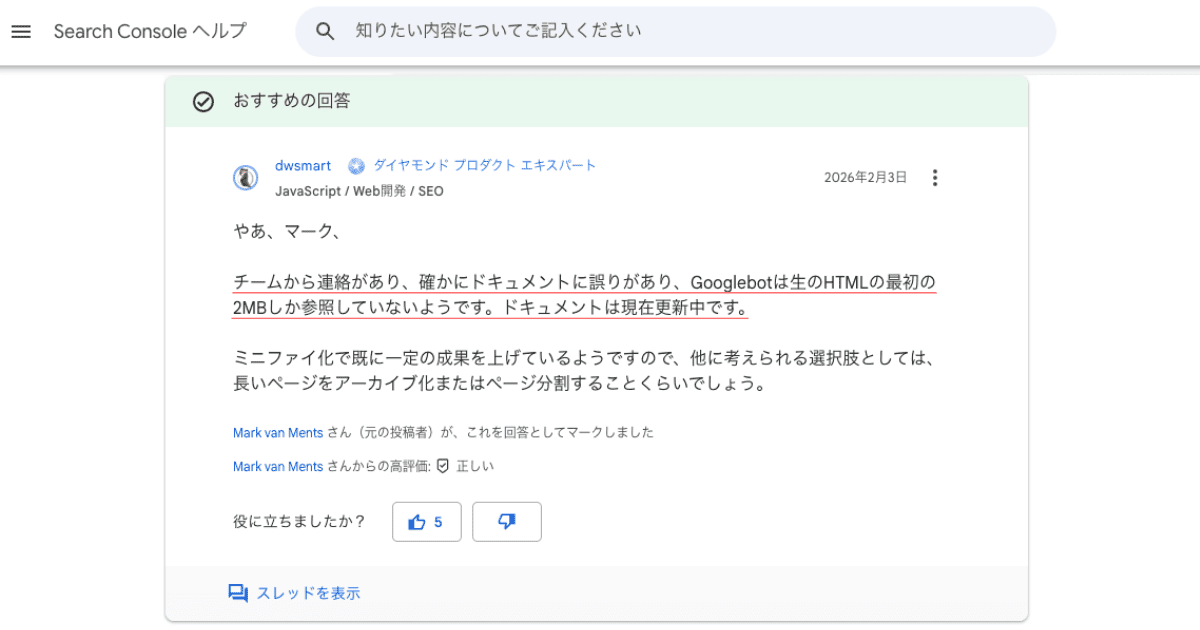
引用:確かにドキュメントに誤りがあり、Googlebotは生のHTMLの最初の2MBしか参照していないようです(Search Console ヘルプ)
調査の結果、2026年2月3日にダイヤモンドプロダクトエキスパートのdwsmartがGoogleチームの確認として「ドキュメントに誤りがあり、GooglebotはHTMLの最初の2MBしか参照していない。ドキュメントは現在更新中」と回答。
その後、公式ドキュメントが更新され、Googlebotのクロール上限が2MBと正式に明記されました。これは仕様の変更ではなく、もともと2MBで動作していた実態に合わせてドキュメントを修正したものとされています。
Googlebotの2MBクロール制限|ページ容量の確認方法3つ
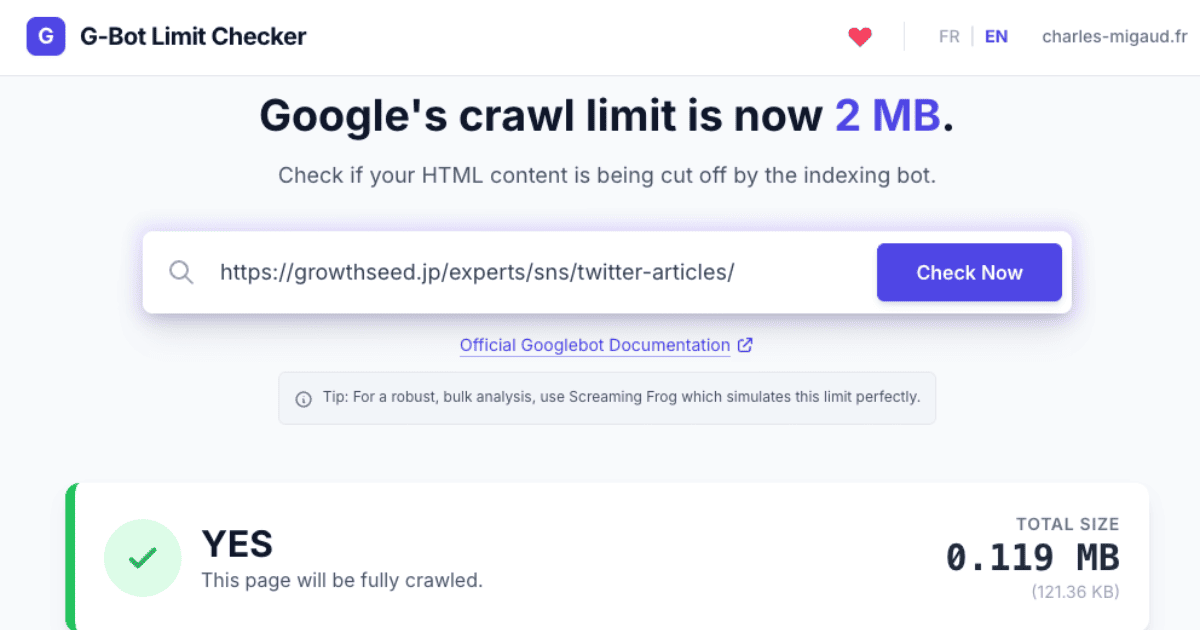
Googlebotの2MB制限はHTMLファイル単体に適用されるものであり、画像や動画などのメディアファイルは別枠で取得されます。日本語テキストは1文字あたり3〜4バイトのため、2MBに達するには50万文字以上が必要であるため、通常のWebページで2MBを超えることはほぼありませんが、念のため自分のサイトを確認しておきたい場合は以下の方法を参照してください。
手動でHTMLファイルサイズを確認する方法
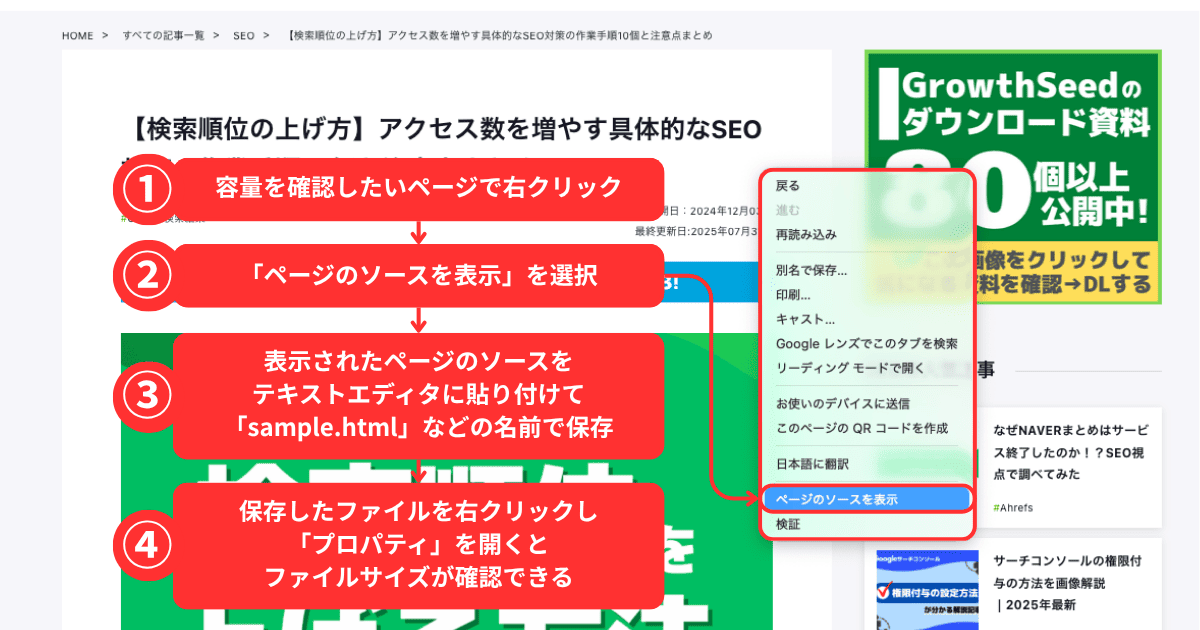
確認したいページをブラウザで開き、右クリックから「ページのソースを表示」を選択します。表示されたHTMLコードをCtrl+Aで全選択してコピーし、テキストエディタに貼り付けて「sample.html」などの名前で保存します。
保存したファイルを右クリックして「プロパティ」を開くと、ファイルサイズを確認できます。Googlebotの2MB制限は圧縮前(非圧縮)のファイルサイズに適用されます。
AhrefsのSite Auditで2MB超過ページを自動検知する方法
🆕 重要!サイト監査が「2MB」を超えるページを自動検知!
Googleが最近ドキュメントを更新し、「Googlebotは非圧縮HTMLの最初の2MBのみをクロール」 と明記しました。
【影響】
2MB以降に配置された:
❌ 重要なテキスト
❌ 内部リンク
❌ 構造化データ
→ Googleに認識されていない可能性… pic.twitter.com/GitJ1Be6VI— Ahrefs Japan 公式 (@AhrefsJP) April 1, 2026
AhrefsのSite Auditには「Googlebot’s 2MB crawl limit」という専用のチェック項目が追加されており、サイト内で2MBを超えるHTMLページを自動的に検出して一覧表示できます。非圧縮サイズをバイト単位で確認できるため、どのページがどの程度超過しているかを具体的に把握できます。
Ahrefsはサイト全体を一括チェックしたい場合に有効な手段です。なお、2026年4月時点では無料版での確認はできないため、有料プランでの利用が前提となります。
外部のHTMLサイズチェッカーで確認する方法
URLを入力するだけでそのページのHTMLファイルサイズを無料で計測できる外部ツールが存在します。サイト全体の一括チェックには対応していませんが、「この記事は文字数が多いから心配」といった特定のページを個別に確認するのに適しています。
Googlebotの2MBクロール制限に引っかかるリスクがあるHTMLの書き方
画像をBase64エンコードしてHTMLに直接埋め込んでいる場合
Base64エンコードとは、画像をテキストデータに変換してHTMLに直接埋め込む手法です。HTTP/1.1時代には「リクエスト数を減らす」ことが表示速度改善の定石とされており、画像をBase64エンコードしてHTMLに埋め込むことが一般的でした。しかしこの手法を使うと、画像データがそのままHTMLのサイズに加算されます。
例えば500KBの画像4枚をBase64エンコードして埋め込んだ場合、それだけで2MBに達してしまいます。古い高速化設定を引き継いだまま運用しているサイトや、古い手法を採用した制作会社が構築したサイトでは、この問題が発生している可能性があります。
CSS・JSをHTMLにインライン記述している場合
CSSやJavaScriptのコードをすべて<style>タグや<script>タグとしてHTMLファイル内に直接記述している場合も、HTMLファイルのサイズが大幅に増加します。ページ固有のスタイルや軽微なスクリプトをインラインで記述すること自体は問題ありませんが、サイト全体で共通して使用する大量のCSSやJSコードをHTMLに吐き出している場合は、外部ファイル化を検討する必要があります。
GooglebotのHTMLクロール上限2MBについてご不安な点はフルスピードにご相談ください
本記事では、GoogleエンジニアのGary Illyes(ゲイリー・イリーズ)がSearch Off the Recordで語ったクローリングの実態をもとに、Googlebotの2MBクロール制限の背景を解説しました。
通常のWebページのHTMLが2MBを超えることはほぼありませんが、画像のBase64エンコードやCSS・JSのインライン記述を大量に行っているサイトでは注意が必要です。まずはページのHTMLサイズを確認し、心当たりがある場合は実装の見直しを検討してみてください。
「自分のサイトのHTMLサイズが2MBを超えているかもしれない」「確認してみたが、どう対処すればいいかわからない」といったご不安をお持ちの方は、フルスピードまでご相談ください。GooglebotのHTMLクロール上限をはじめとするSEOの技術的な課題に関するご相談を承っています。
\Webサイトのお悩みはフルスピードにお任せください/
SEO最新情報やSNS最新情報をまとめて確認してみましょう

↑GrowthSeedが提供する”今話題のSEO最新情報”をチェックする
株式会社フルスピードが運営するオウンドメディアGrowthSeedでは、SEOとSNSの最新情報を素早くキャッチして記事コンテンツとしてまとめています。これまでのSEO最新情報が上記バナーから確認できますので、SEO最新情報の収集目的でご活用ください。
株式会社フルスピードのSEO関連サービスのご紹介

Webサイト
コンサルティングSEO、コンテンツSEO、UIUXの三軸でアプローチし、流入数・コンバージョンをアップさせます。
SEOコンサルティングサイト課題や問題の本質をつかみ、先を見据えた戦略策定と課題解決に繋がるSEOコンサルティング
法人向けSEO研修企業のマーケティング担当者が第一線のプロからSEOを学べるリスキリングサービスです。
株式会社フルスピードは世界で60万人が導入する最高水準のSEO分析ツールAhrefsのオフィシャルパートナーでもあり、これまで培ってきたSEOノウハウとAhrefsのサイト分析力を活かしたSEOコンサルティングサービスをご提供することが可能です。SEOコンサルティングサービスの詳細に関しましては上記バナーをクリックしご確認ください。お気軽にご相談ください。
この記事を書いた人
記事の関連タグ






SEOの人気記事
-

なぜNAVERまとめはサービス終了したのか!?SEO視点で調べてみた
-

サーチコンソールの権限付与の方法を画像解説┃2025年最新
-

GA4とサーチコンソールの連携方法!メリット・確認方法・連携できない時の対処法まとめ
-

CLSとは? 低下要因と改善方法をわかりやすく解説
-

Googleサーチコンソールとは?設定~活用までの基礎を解説【2025年最新版】
SEOの新着記事
-

GoogleがAI検索に「優先ソース」を拡大!AI OverviewsとAIモードでお気に入りサイトが優先表示可能に!
-

GoogleがFAQリッチリザルトのサポートを終了!廃止スケジュール3段階と構造化データの扱いを解説
-

GoogleがAI OverviewsとAIモードのアップデートを発表!ウェブ探索を強化する5つの新機能を紹介!
-

低品質な外部リンクを受ける影響は?「無視する可能性がある」とジョン・ミューラー氏が回答
-

「戻るボタンで戻れない」のボタン不正操作行為に新しいスパム対策ポリシーを導入(Google)
関連タグから記事を探す