

パンダアップデートの生みの親が出願した特許をご紹介します。
Googleが開発した関連キーワードをデータベース化する技術の特許
公開日:2014年04月30日
最終更新日:2024年02月27日

こんにちは。アナリストの荒木です。
検索エンジンの精度を高めるため、新しい技術や仕組みが日々開発されています。そういった発明が行われた際には特許が取得されており、その内容を私たちも閲覧することが可能です。
とはいえ、翻訳が必要であったり専門用語が頻出したりと、内容を理解するのはなかなか難しいものです。そういった検索エンジンに関する特許を解説していきたいと思います。
(特許に掲載されている技術が、Googleの検索アルゴリズムに導入されている保証はありませんのでご注意ください。)
第一回目は、「クエリ(検索窓に入力した単語)に対する検索結果の精度を向上させるための技術」についてご紹介します。
ご紹介する特許の全文は、下のリンクからご覧いただけます。(別ウィンドウでPDFデータが表示されます)
【今回取り扱う特許】
特許名:Query Generation Using Structural Similarity Between Documents
※関連性の高いキーワードに関するWebページを検索結果に含めることにより、精度を向上させる技術について書かれています。
↓株式会社フルスピードのSEOコンサルティングサービスのご紹介(資料DLページ)
目次
目次
- 関連キーワードが検索エンジンに必要な理由
- 関連キーワードが検索エンジンへ適用される想定効果
- 関連キーワードが出来るまでの大まかな流れ
- 関連キーワードが出来るまでの詳細な流れ
- まとめ
1.関連キーワードが検索エンジンに必要な理由
Googleは2003年以降、過去に検索されたことがない4,500億もの新ユニーク検索クエリに応答しており、関連する情報を検索ユーザーに届ける努力をしています。しかし、広義なクエリでは蓄積された既存の情報だけでは判断が難しい場合があり、検索エンジンはユーザーが求める情報を上位に表示出来ない可能性があります。
この打開策として、検索エンジンはユーザーの意図を独自に判断し、広義なクエリの関連キーワードを検索結果に含む技術を開発しました。関連キーワードをあえてプラスすることで、ユーザーが求めるであろう情報を検索結果に表示出来るようになっています。
2.関連キーワードが検索エンジンへ適用される想定効果
- クエリの検索結果に関連キーワードの検索結果を差し込むことで、検索結果数を増やす
- クエリの関連キーワードに紐づく広告を表示する
- 関連キーワードの関連キーワードを作り、単語のネットワークを構築する
3.関連キーワードが出来るまでの大まかな流れ
- クエリが投げられ、検索結果の中からサイトを選択
- PV数が多いページや滞在時間が長いページを選択し、そのサイトをクロール
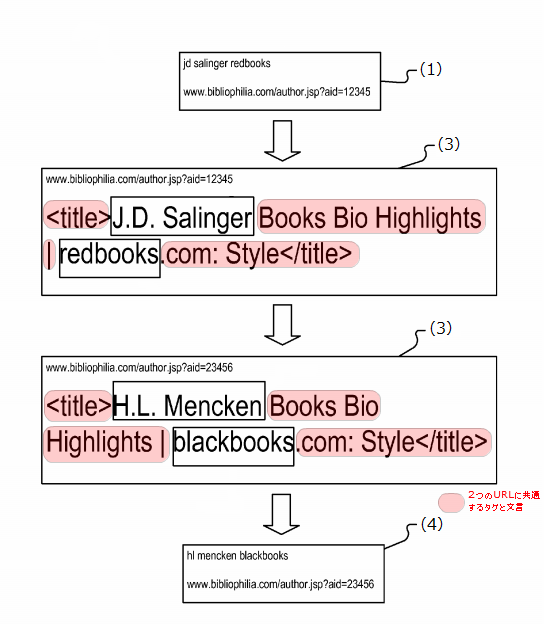
- サイト内で同じテンプレート(※)を使っている部分を抽出
- 関連キーワードを見つける
※下図において、titleタグと「Books Bio Highlights|」「.com:Style」のように共通した文言とタグがあります。これをテンプレートと呼んでいます。
4.関連キーワードが出来るまでの詳細な流れ
※以下の説明では、[<h1>○○-biography</h1>] と [<h1>xx-biography</h1>]を同じテンプレートの例として説明します。
- 検索ユーザーがクエリ「○○」を検索エンジンに投げます。
- 関連キーワードを取り出すサブシステムが、○○の検索結果上でよくクリックされているサイトとGoogleのデータベースからHTMLを取得します。
- 関連キーワード抽出システムが、[<h1>○○-biography</h1>] と [<h1>xx-biography</h1>]のように<h1>+「-biography」というテンプレートを使っているパーツを抽出します。
- 「○○の関連キーワードは✕✕」として関連キーワードデータベースに登録します。

5.まとめ
この技術がそのまま導入されると、関連キーワードに関する検索結果が、クエリに関する検索結果に差し込まれます。
その場合、ユーザーは「スティーブ・ジョブズ」で検索した際に、ビル・ゲイツやティム・クックの情報が検索結果に表示され、一度に様々な偉人を知ることができます。
一方で、関連キーワードの一部の検索結果が差し込まれた場合、今までは表示されていなかったページが表示される可能性が考えられます。
株式会社フルスピードのSEOコンサルティングサービスのご紹介
↓株式会社フルスピードのSEOコンサルティングサービスのご紹介(資料DLページ)
株式会社フルスピードはSEOコンサルティングサービスをご提供しています。株式会社フルスピードは2001年の創業から5,500社以上ものSEOコンサルティング実績を積み上げてまいりました。
株式会社フルスピードは世界で60万人が導入する最高水準のSEO分析ツールAhrefsのオフィシャルパートナーでもあり、これまで培ってきたSEOノウハウとAhrefsのサイト分析力を活かしたSEOコンサルティングサービスをご提供することが可能です。SEOコンサルティングサービスの詳細に関しましては上記バナーをクリックしてご確認くださいませ。お気軽にご相談ください。
この記事を書いた人
記事の関連タグ





