【Google最新情報】検索結果に「この結果について」パネルと「下記の検索結果がすばやく変わってしまう」表示のリリースを発表
クラスタ分析:機械学習で行うデータ分析手法の紹介
公開日:2015年03月30日
最終更新日:2024年02月27日

こんにちは。アナリストの荒木です。
以前ご紹介した機械学習アルゴリズムのなかで、導入がとても簡単なクラスタ分析を紹介します。
今回ご紹介する方法は、環境のインストールからデータ分析実施まで合わせて1時間もかかりませんので、少し手の空いた時間に試していただければ幸いです。
↓株式会社フルスピードのSEOコンサルティングサービスのご紹介(資料DLページ)
目次
クラスタ分析とは
クラスタ分析とは、さまざまな個体を一定の手順に基づいて似ている集団(クラスタ)に分類し、その中から意味あるものを発見する分析方法です。
ポジショニングマップも個体を分類する手法ですが、軸が3次元、4次元と増えるにつれ、どのように分類すべきかで迷ってしまうことがあります。
例えば、検索エンジンで集客したページを分類した場合、以下のようにパターンが考えることができます。
- 検索順位は上位表示しているけど、CTRが低く流入につながっておらず、離脱率の低いページ
- 流入はたくさんあるけど、直帰率が高く、コンバージョンへ貢献しにくいページ
- 流入がたくさんあり、直帰率も低いが、閲覧時間が短いページ
- 表示回数が多く、CTRも高く、閲覧時間も長いが、離脱率が高いページ
クラスタ分析では3次元以上の軸であっても、自動的に似ているページを集めることで、その特徴を知ることができます。
クラスタ分析に利用するデータ
今回は、AppVIPのコラム記事のアクセスデータを使って、クラスタ分析を行います。
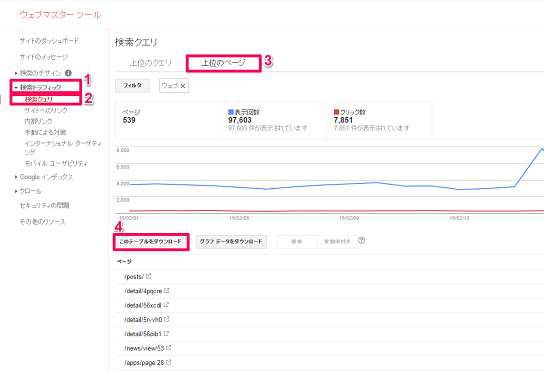
1.Googleウェブマスターツールからダウンロードする
[検索トラフィック] → [検索クエリ] → [上位のページ] → [このテーブルをダウンロード]
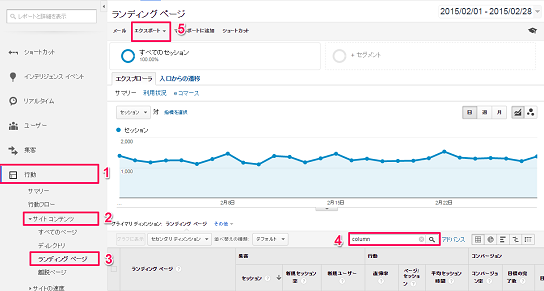
2.Googleアナリティクスからダウンロードする
今回は、コンテンツSEOのページ毎の閲覧開始データをダウンロードします。
[行動] → [サイトコンテンツ] → [ランディングページ] → 検索窓からディレクトリを指定 → [ダウンロード]
※特定ページの確認方法はこちらをご確認ください。
※集計対象期間をGoogleウェブマスターツールと合わせてください。
3.GoogleウェブマスターツールとGoogleアナリティクスをURLで紐づけたデータを用意する
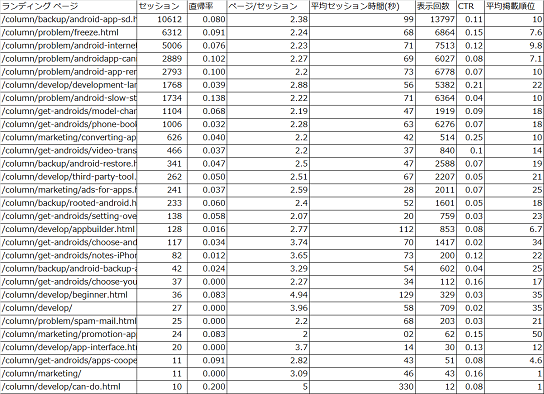
エクセルで、GoogleウェブマスターツールとGoogleアナリティクスのデータを紐づけます。
今回は、[セッション][直帰率][ページ/セッション][平均セッション時間][表示回数][CTR][平均掲載順位]
以外の余分な軸を削除します。
▼加工後のデータ
※エクセルで加工する場合は[http://domain]を削除し、URLをキーにしてvlookup関数で紐づけてください。
※すべて数値データに変換してください。
Rで書くクラスタリング
Rはオープンソースの統計解析言語です。こちらからダウンロードいただけます。
クラスタリングアルゴリズムは、機械学習アルゴリズムまとめで紹介した、K-meansという手法を用います。
K-meansは、あらかじめグルーピングする数(クラスタ数)を決める手法ですので、AppVIPのコラム記事のページを4クラスタに分類します。
手順は以下の通りです。
1.用意したデータを環境にロード
accessData <- read.csv("access_data.csv")2.URL(1列目)データ以外の値でクラスタリング
result <- kmeans(accessData[,-1],4)3.クラスタの平均値を出力する
write.csv(result$centers,"centers.csv")4.各ページが所属するクラスタを出力する
write.csv(cbind(accessData,result$cluster),"result_kmearns.csv")データ分析方法
クラスタの特徴を確認する
クラスタ毎に、各軸の平均値を確認します。

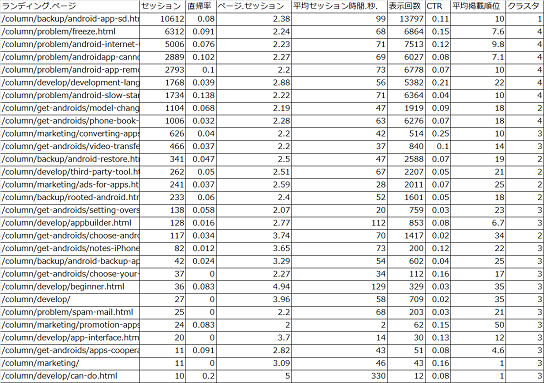
クラスタ1は、「セッションが多いが、他ページへの誘導が少なく、平均セッション時間が長い」という特徴から、”人気独占コンテンツ”と呼ぶことにします。
クラスタ2は、「セッションは少ないが、ほかページに誘導している。一方で、平均セッション時間が短く、順位とCTRが低い」という特徴から、”ほかページへの誘導が早いコンテンツ”と呼ぶことにします。
クラスタ3は、「セッションは少ないが、平均セッション時間が長く、ほかページに誘導している。順位とCTRが低い」という特徴から、”読んだ後に他ページへ誘導しているコンテンツ”と呼ぶことにします。
クラスタ4は、「セッションが多いが、他ページへの誘導が少なく、平均セッション時間が短い」という特徴から、”内容が薄い人気コンテンツ”と呼ぶことにします。
クラスタの特徴から改善点を考える
各クラスタの特徴から、以下の改善点を考えることができます。
クラスタ1 ”人気独占コンテンツ”:関連ページへのリンクを設置するなど、他ページへの回遊を促す。
クラスタ2 ”ほかページへの誘導が早いコンテンツ”:順位上昇とCTRの改善を視野に入れたタイトルの書き換えを行い、ページ内コンテンツを追加する。
クラスタ3 ”読んだ後に他ページへ誘導しているコンテンツ”:順位上昇とCTRの改善を視野に入れたタイトルの書き換えを行い、サイト内からのリンクを増やす。
クラスタ4 ”内容が薄い人気コンテンツ”:ユーザーが求めていると考えられる、深堀したコンテンツをページ内に追加する。
▼クラスタと各ページの関係
まとめ
クラスタ分析は、複雑に絡み合ったパターンも、クラスタ数を限定することでその集団の特徴を確認することができます。
また、クラスタごとの改善点がそのまま各ページの改善につなります。
Rを使うと簡単に着手できますので、本記事が機械学習を始めるきっかけになれば幸いです。
最後までご覧いただきありがとうございました!
株式会社フルスピードのSEOコンサルティングサービスのご紹介
↓株式会社フルスピードのSEOコンサルティングサービスのご紹介(資料DLページ)
株式会社フルスピードはSEOコンサルティングサービスをご提供しています。株式会社フルスピードは2001年の創業から5,500社以上ものSEOコンサルティング実績を積み上げてまいりました。
株式会社フルスピードは世界で60万人が導入する最高水準のSEO分析ツールAhrefsのオフィシャルパートナーでもあり、これまで培ってきたSEOノウハウとAhrefsのサイト分析力を活かしたSEOコンサルティングサービスをご提供することが可能です。SEOコンサルティングサービスの詳細に関しましては上記バナーをクリックしてご確認くださいませ。お気軽にご相談ください。
この記事を書いた人
記事の関連タグ